CKAD Prep Guide by Wriju
Linux Bash, Vim, Docker, Kubernetes
CKAD - Certified Kubernetes Application Developer
Preparation Guide by Wriju Ghosh (@wrijugh)
Introduction
There are handful of CKAD professionals today. However probably there are few hundred resources explaining about their own experiences on this intense hands-on exam. Then the question might arise why yet another such guide. I would try to justify the reason behind my intention to put together the content.
I think it might be helpful for the people like me around. I come from Windows background. I have a very limited experience working on Linux. However, I’ve been fortunate enough to work with my customers helping move their workloads in cloud managed Kubernetes platform. Also, my organization arranges hands-on OpenHack events to help experience the real-life example on Kubernetes deployment. I’ve learned a bit while working as well as understood that conceptually I’m far behind to really understand why one over another. I started digging into the concepts of Kubernetes and slowly explore things like I never knew before. Then I realized that to validate my working experience with the concept from my learning needs a validation. Let me try the well-known and well-recognized exam i.e., Certified Kubernetes Application Developer aka, CKAD. Because this will not only ensure my knowledge gap but also recognize the effort if I’m putting it in the right direction.
It’s a journey by all means. Even in the toughest circumstances if I could not clear the exam after multiple try, I would have been happy to have it prepared because while preparing I’ve learned and cleared many of my vague understanding about the main Kubernetes platform. That’s why I would like to call it as journey that matters.
Some facts about CKAD
- CKAD has a word developer. But his does not ask you to write any application or configure. Hence anybody can sit for this exam and no matter whether you come from a development background or not. I think CNCF may consider renaming this “developer” into something like “DevOps” this will help reduce the confusion.
- This is a performance-based exam. A browser-based console will be given to work on. There is no need to install any additional software apart from a small extension for the Chrome or Chromium browser.
- For the exam environment details and candidate Handbook please visit the official CNCF portal for the most up-to-date details. I would highly recommend not to rely on any individual, independent or third party blog about the exam environment, because the information can go outdated.
- Candidate Handbook
- Curriculum - refer this for latest one
- Very useful Exam Tips
- Practice Practice Practice - key to the success. Once you are comfortable solving the problems go for time bound practice. Use stopwatch and solve as quickly as possible. If you are well prepared then probably there is no problem which you can’t solve. Time management is the key.
Steps to prepare
Since the exam happens in a Linux terminal having an understanding and comfort working with Linux is the key success factor here. You need to be comfortable with basic Linux commands, simple bash scripts, and the most important of all is very comfortable with Vim editor. If you struggle during the exam while copying a content from documentation to Vim and format is damaged, then you will be losing out your precious time. So get used to with Vim and try to be faster as much as possible. There are a lot of tips and tricks available online go through some of them as you are working on to editing/modifying YAML files.
If you are already a seasoned Linux user then you may skip the below step and go directly to the core Kubernetes Objects and Concepts.
I have designed the below steps keeping in mind that the candidate it’s not comfort working with Linux. Either they come from pure Windows background or new to Linux world.
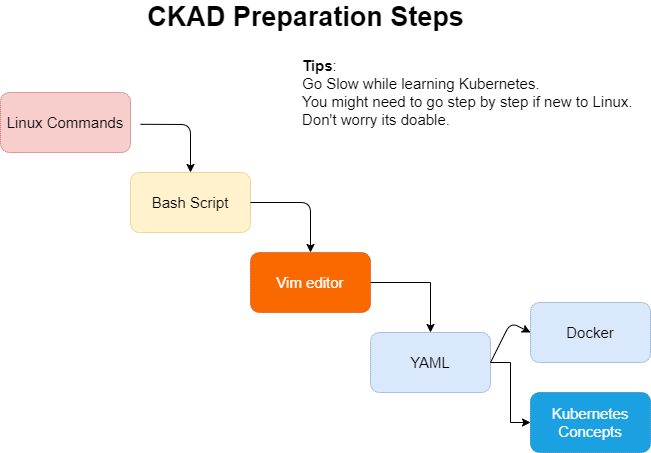
Now let’s handle them one by one:
Setup Dev Box
Optional Setup Ubuntu Dev VM in Azure
Basic Linux Commands
You will encounter often times with the Linux command prompt. Because the CKAD exam uses one of the Linux distributions. If you happen to not come from the Linux world it’ll be intimidating. You might get stuck on few things due to the lack of practice. Hence it is absolutely important to feel comfortable with Linux commands, at least the basic file handling etc.
Basic Shell Scripting
Bash script or Shell script it’s not that important but it keeps popping up while you work on container. For example, you might need to run a command which will keep your container running for 3600 seconds. If you know bash script, then you know there is command called sleep followed by the number of specified well keep your interactive terminal wedding for the specified seconds. These are not very in-depth automation kind of script you have to understand but good to know some basic Shell scripts construct which will help you during the exam as well as while working with Kubectl.
Vim Editor
Vim or Vi modified is the default editor for Linux operating system. Unlike other text editors like notepad, sublime, notepad++, word processor – Vim plays in a completely different world. People coming from non Linux background using Windows for the first time can get frustrated with the weird behavior. But for a seasoned Linux users it is the most efficient editors ever available in Linux. If you happen to see a Linux user working on vim, you will be amazed to see how fast it can go. If you know the tricks you can do magic. In this short video I tried to demonstrate the capabilities from a purely Windows user perspective. Hope you will enjoy this will too.
Intro to YAML
I found this nice 18 min video from Nana. I recommend we all watch this. This basic understanding would help. Because it is the backbone of Kubernetes.
Introduction to YAML - by Wriju
Docker Basics
Kubernetes runs container. But it is not mandatory to have only docker as its container runtime. The default comes with docker. However, Kubernetes manages Pod not the container. Having a little bit of idea about how Docker container works could help clarify some of the command line activities to understand the basics. Let’s have a small video.
Introduction to Docker containers
Kubernetes under 10 minutes
CKAD exam is a performance-based exam. That means you will be given Linux console and asked to solve certain problems. There is no objective type question. You not only have to know Kubernetes hands-on but also be very comfortable and quick in solving the problems. In this section I wil try to share some of the tips and tricks of using CLI Kubectl and configuring basic building blocks.
Kubernetes CKAD Tips 1 - Using Katacoda - A free Kubernetes Playground
Katacoda is a nice place to start with Kubernetes. It is a browser-based playground and does not require any local installation. One can start immediately without spending much time on setting up the Kubernetes locally or in a VM.
This video talks about how we can use Katacoda.
Kubernetes CKAD Tips 2 - Breaking the myths - CKAD does not require programming knowledge
CKAD (Certified Kubernetes Application Developer) the word “Developer” does not mean that it will ask you to write code. If you have no development experience and never done any programming work, don’t worry - none of those skills are required here. You can still sit for the exam and clear with a flying color. So have a look into the CNCF’s official curriculum and jump into it.
Kubernetes CKAD Tips 3 - Pod and Container
In Kubernetes we need to manage Pod which hosts the container(s). In Kubernetes what is the relationship between pod and container? The concept of Pod is unique in Kubernetes. Let’s understand it a bit.
Kubernetes CKAD Tips 4 - Troubleshooting Pods
When you create a Pod it generally gets created if the syntax is correct. At least the CLI says so. It is mainly because the Kubernetes API checks everything and accepts the instruction. Later the Kubernetes scheduler picks it up and deploys. By the time it is accepted to the time it is deployed many things could happen. Also, if the image used in Pod’s container is wrong Kubernetes API can’t figure it out unless it deploys it. So, it gets to know about the image unavailability during the creation process. Also, there could be an issue with available CPU and memory of the Node. Let’s see the different ways to build and deploy the Kubernetes Pod and if any problem how to find it out and can be sorted.
Kubernetes CKAD Tips 5 – Namespaces
Kubernetes supports multiple virtual clusters backed by the same physical cluster. These virtual clusters are called namespaces. Names of the resources within a Namespace should be unique. Namespaces cannot be nested.
Kubernetes CKAD Tips 6 – Configuring Kubectl context
Often time we work with multiple Kubernetes clusters and namespaces from a single console. Hence switching between the clusters and console is important. Let’s learn few kubectl command to do it switching.
Kubernetes CKAD Tips 7 – Getting help
In my opinion Kubernetes CLI documentation is the best. You get pretty much everything you need including the syntax help with examples. Let’s learn how to use the CLI help.
Kubernetes CKAD Tips 8 – Deployments
A Deployment provides declarative updates for Pods and ReplicaSets. You describe a desired state in a Deployment, and the Deployment Controller changes the actual state to the desired state at a controlled rate. You can define Deployments to create new ReplicaSets, or to remove existing Deployments and adopt all their resources with new Deployments.
Kubernetes CKAD Tips 9 – Rolling Updates in Deployment
In a real production environment, we don’t manage Pods rather Kubernetes deployment manages the Pods. However, if there is a change or update required, we prefer not to shut down the whole environment but rather roll it over slowly. If you have four replicas then probably it will take down one at a time and update 4 pods one after another, rather than doing altogether. This purely depends on the requirement of your application, if you don’t want to have any older version running while updating the newer version, you can have the complete update without choosing the rollout kind of behavior.
Kubernetes CKAD Tips 10 – Labels
Labels in Kubernetes are a very humble but important component. Through labels Kubernetes objects like deployment, services are connected to the core component Pod. Labels are not mandatory. You can create an object without a Label. Labels can be added or modified later as well. Together with selector label helps connect loosely coupled objects.
Kubernetes CKAD Tips 11 – Annotations
You can use Kubernetes annotations to attach arbitrary non-identifying metadata to objects. Clients such as tools and libraries can retrieve this metadata. You can use either labels or annotations to attach metadata to Kubernetes objects. Labels can be used to select objects and to find collections of objects that satisfy certain conditions. In contrast, annotations are not used to identify and select objects. The metadata in an annotation can be small or large, structured or unstructured, and can include characters not permitted by labels.
Kubernetes CKAD Tips 12 – Jobs
A Job creates one or more Pods and will continue to retry execution of the Pods until a specified number of them successfully terminate. As pods successfully complete, the Job tracks the successful completions. When a specified number of successful completions is reached, the task (ie, Job) is complete. Deleting a Job will clean up the Pods it created.
Kubernetes CKAD Tips 13 – CronJobs
A CronJob creates Jobs on a repeating schedule. Say a Pod which reminds you to take breakfast every morning at 7 AM.
Kubernetes CKAD Tips 14 – Services (ClusterIP, NodePort, LoadBalancer)
Pod and deployments are well thought through design components. They help do the horizontal scaling. But what happens when you have more than one Pods how the load balancing would happen. Which IP address the user would connect to? Services comes into play then. Services helps expose Pod(s) via ClusterIP, NodePort or LoadBalancer(to the external world). This enables the Pods to talk to each other. For example if you have a backend Pod that needs to talk to frontend web applications then we don’t connect one pod to another we rather expose them via Service endpoint and connect to each other. Pods are non-persistent which means that they can be recreated by the Kubernetes Scheduler or some change by the system and may also get allocated to another node which has a different IP address altogether. This way Pods are not reliable for DNS mapping. We need something like Kubernetes Service to dynamically select Pods using its labels and map them to the endpoints. That is why Services are key important elements in Kubernetes.
Kubernetes CKAD Tips 15 – Multi-container Pod
A Pod generally runs one container most of the time. But it is capable of running more than one containers. So a single pod can host two containers supporting each other for an application need. Assume that your application will cache the data in Redis which is another container. You can host both Application and Redis in same pod. This becomes easier to manage. Also using multi-container we can check the initialization process for an application. In that case we use InitContainer concept. Other kind of multi container patterns include Sidecar and Ambassador pattern.
Kubernetes CKAD Tips 16 – Init Container
A Pod can have multiple containers running apps within it, but it can also have one or more init containers, which runs before the app containers are started.
Init containers are exactly like regular containers, except:
-Init containers always run to completion. -Each init container must complete successfully before the next one starts.
If a Pod’s init container fails, the kubelet repeatedly restarts that init container until it succeeds. However, if the Pod has a restartPolicy of Never, and an init container fails during startup of that Pod, Kubernetes treats the overall Pod as failed.
Kubernetes CKAD Tips 17 – Liveness Probe
The kubelet uses liveness probes to know when to restart a container. For example, liveness probes could catch a deadlock, where an application is running, but unable to make progress. Restarting a container in such a state can help to make the application more available despite bugs.
Kubernetes CKAD Tips 18 – Readiness Probe
The kubelet uses readiness probes to know when a container is ready to start accepting traffic. A Pod is considered ready when all of its containers are ready. One use of this signal is to control which Pods are used as backends for Services. When a Pod is not ready, it is removed from Service load balancers.
Kubernetes CKAD Tips 19 – Startup Probe
The kubelet uses startup probes to know when a container application has started. If such a probe is configured, it disables liveness and readiness checks until it succeeds, making sure those probes don’t interfere with the application startup. This can be used to adopt liveness checks on slow starting containers, avoiding them getting killed by the kubelet before they are up and running.
Kubernetes CKAD Tips 20 – Volume Mount
Inside a Pod in a Container there could be a requirement to save the file or read from. In this case we can create a mapped folder in the container pointing to an external storage (could be cloud too). That way in a multi-container Pod scenario we can write to a file and read the same file from two separate containers. There are many ways to create this mapped drive. We will see the {EmptyDir} option which creates a temp directory in the Node. You can also select the external persistent storage like Cloud Storage. This will be there even if the Node is re-created.
Kubernetes CKAD Tips 21 – Container Port
Often container hosts an application which is available via a specific port. For example, the Nginx container uses Port 80 to expose the http endpoint. If there is a specific port which needs to be exposed, we can do so by defining containerPort in the YAML.
Kubernetes CKAD Tips 22 – Persistent Volume
Managing storage is a distinct problem from managing compute instances. The PersistentVolume subsystem provides an API for users and administrators that abstracts details of how storage is provided from how it is consumed. To do this, we introduce two new API resources: PersistentVolume and PersistentVolumeClaim. A PersistentVolume (PV) is a piece of storage in the cluster that has been provisioned by an administrator or dynamically provisioned using Storage Classes. It is a resource in the cluster just like a node is a cluster resource. PVs are volume plugins like Volumes but have a lifecycle independent of any individual Pod that uses the PV. This API object captures the details of the implementation of the storage, be that NFS, iSCSI, or a cloud-provider-specific storage system. A PersistentVolumeClaim (PVC) is a request for storage by a user. It is like a Pod. Pods consume node resources and PVCs consume PV resources. Pods can request specific levels of resources (CPU and Memory). Claims can request specific size and access modes (e.g., they can be mounted ReadWriteOnce, ReadOnlyMany or ReadWriteMany).
Kubernetes CKAD Tips 23 – Environment variables
Environment Variables are like the config values of an application. Instead of passing them as part of a text file in a containerized application, we can have them as Environment variables. That way in every deployment we could change as needed. They are needed but they don’t belong to the codebase. Here is a quick way how we can add them to a container inside a Pod and then modify when needed in YAML.
Kubernetes CKAD Tips 24 – ConfigMaps Create from literals, env files and txt files
A ConfigMap is an API object used to store non-confidential data in key-value pairs. Pods can consume ConfigMaps as environment variables, command-line arguments, or as configuration files in a volume. A ConfigMap allows you to decouple environment-specific configuration from your container images, so that your applications are easily portable.
Kubernetes CKAD Tips 25 – ConfigMaps as single or more env variables
Using the ConfigMap object how can we populate an environment variable (one or more).
Kubernetes CKAD Tips 26 – ConfigMaps as all values in env variables
Using the ConfigMap object how can we populate set of environment variables. No matter how many keys we have in the ConfigMap, this process would produce the list of Environment variable from that.
Kubernetes CKAD Tips 27 – ConfigMaps as Volume Mount
How can we mount ConfigMaps keys as files in a mapped volume inside a Pod. This way we have n number of files inside a folder where this n is the total number of Keys within a ConfigMap.
Kubernetes CKAD Tips 28 – Secrets Create and View
Kubernetes Secrets let you store and manage sensitive information, such as passwords, OAuth tokens, and ssh keys. Storing confidential information in a Secret is safer and more flexible than putting it verbatim in a Pod definition or in a container image.
Kubernetes CKAD Tips 29 – Secret Load as volume
Load Secrets as volume and mount that to a container. They key(s) will become the file(s) name and the value(s) (decoded) are the text within the file(s).
Kubernetes CKAD Tips 30 – Secret Load as env variable
You can populate one or more environment variable from Secret object.
Kubernetes CKAD Tips 31 – Pod Limits Memory and CPU
When we create Pod we can set the minimum and maximum limit of CPU and Memory. That way we can ensure the best performance of our container and have the right node to host this as well.
Kubernetes CKAD Tips 32 – Node memory and CPU usage
Using kubectl top we can find the current node memory and cpu usage to understand if we have enough space available to host yet another Pod.
Kubernetes CKAD Tips 33 – Network Policy
This is best video on Network Policy explained. Please watch
Kubernetes CKAD Tips 34 – Kubectl General Tips
Kubeclt is the ClI for Kubernetes. There are few tips I have shared here. There are many and getting comfortable is the key here.
Kubernetes CKAD Tips 35 – CKAD Exam Tips
More coming soon…
Subscribe to the Channel TechTalks-Wriju